Another presentation I gave at the General Online Research (GOR) conference in March1, was on our first approach to using topic modelling at SKOPOS: How can we extract valuable information from survey responses to open-ended questions automatically? Unsupervised learning is a very interesting approach to this question — but very hard to do right.
In a first proof-of-concept we implemented an extension of the traditional LDA-algorithm by Blei, Ng, and Jordan (2003), namely “Embedding-based Topic Modelling” (Qiang et al., 2016). The algorithm uses the magic of word embeddings to incorporate knowledge about word relationships into the modelling, which seemed like a good idea when we started.
The general idea of ETM is to use word embeddings at two stages: First, the raw texts are clustered based on document distances (Word Movers Distance; Kusner et al., 2015). Second, the LDA model is extended by edges between topic assignments if words are similar, i.e. similar words should more likely be assigned the same topic (effectively performing a MRF-LDA, Xie et al., 2015). Both steps are computationally very expensive — possibly a reason why the algorithm has not yet been used very often.
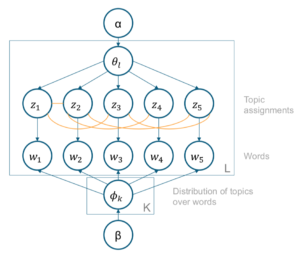
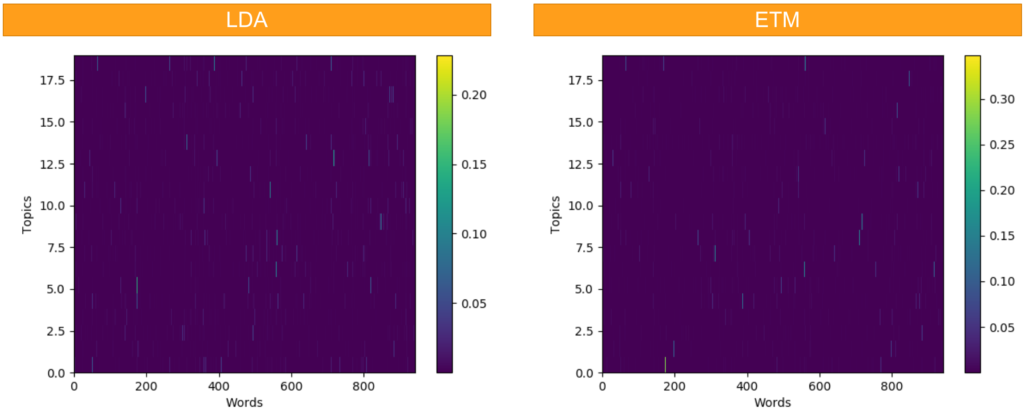
The presentation very briefly explains the models we used and the shows the results of two example data-sets, one in English (Sentiment140) and a proprietary German one.
In contrast to many machine learning papers, our primary focus was on usefulness: Can we and our colleagues in the project teams work with the results from the algorithm? Bottom line: Without proper finetuning of the hyper-parameters the results were quite unsatisfactory for any practical use.
Learnings and Next Steps
We did we learn from our proof-of-concept and what are we are going to do?
- Word embeddings are useful, because they contain pre-trained information which can be used quite efficiently.
- Hyper-parameters need careful tuning and we need to find some useful defaults which work across a variety of projects.
- The implemented k-Means algorithm is very inefficient and can be improved e.g. by using Mini-Batch k-Means or X-Means.
As I’m primarily interested in using the algorithm in real-world projects, I feel that ETM is not yet useful enough to automate a first look on the texts in an unsupervised way. Using word embeddings, k-Means and simple word extraction using a POS-tagger currently seems more fruitful. Nevertheless, I think it is worthwhile to keep looking at LDA extensions — someone might come up with a bright idea and an efficient algorithm.
References
- Blei, D. M., Ng, A. Y., & Jordan, M. I. (2003). Latent Dirichlet Allocation. Journal of Machine Learning Research, 3, 993–1022.
- Kusner, M. J., Sun, Y., Kolkin, N. I., & Weinberger, K. Q. (2015). From Word Embeddings To Document Distances. Proceedings of The 32nd International Conference on Machine Learning, 37, 957–966.
- Qiang, J., Chen, P., Wang, T., & Wu, X. (2016). Topic Modeling over Short Texts by Incorporating Word Embeddings. CEUR Workshop Proceedings, 1828, 53–59. Retrieved from http://arxiv.org/abs/1609.08496
- Xie, P., Yang, D., & Xing, E. P. (2015). Incorporating Word Correlation Knowledge into Topic Modeling. In Conference of the North American Chapter of the Association for Computational Linguistics (NAACL) (pp. 725–734). Retrieved from http://www.cs.cmu.edu/~pengtaox/papers/naacl15_mrflda.pdf
- Yesterday, I blogged briefly about my talk on Replicability in Online Research. ↩